
One of the questions we hear from our customers is “what is 4D Vision”? After all, 3D vision systems are in wide use and well understood. The name 4D Vision implies something beyond 3D technologies. And 3D vision systems are great tools for purposes like measuring an object’s dimensions. But we hear from vision experts about the hardware complexity and customization required to get 3D solutions performing to customer expectations.
What is 4D Vision technology?
We founded Apera AI with the goal of making robotic automation easier by providing robots with human-like vision intelligence. With that goal in mind, it was easy to base our technology on the human vision system.
Human vision pays attention to edges, shadows, color and textures in order to make sense of a cluttered environment. Three-dimensional vision is a byproduct of your brain processing the 2D information.
Apera AI’s 4D Vision also works based on the same principle. Simply put, it is an artificial intelligence (AI) powered stereovision system. 2D+2D=4D.

We have designed a complex neural network that receives the images from two off-the-shelf 2D cameras. The neural network processes them at high speed to detect and locate the objects with sub-millimeter accuracy. By design, we ensured that it could also robustly infer the depth (or the third dimension) passively and without any need for active lighting that structured light cameras use.
Advantages of 4D Vision for robotic guidance
FASTER CAPTURE
The 4D Vision technology image capture process is two 2D snapshots done at the same time, taking around 20ms in normal lighting conditions. This compares to a burst of 10-12 captures done by 3D structured light cameras.
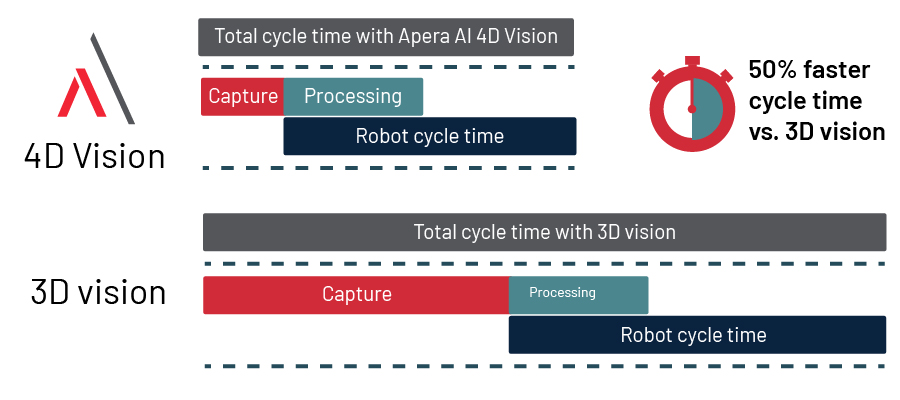
BETTER OVERLAP BETWEEN VISION AND ROBOT CYCLE
As mentioned above, the capturing process for 4D Vision is extremely short, after which the robot can move into the scene. This allows for full robotic cycles of as low as 1.5 seconds per pick. While in case of structured light cameras, capturing takes longer and increases the robot’s cycle time.
FASTER PROCESSING
Depth perception, object recognition and pose estimation is an integral part of the 4D Vision neural network inferencing. Image processing happens extremely fast and becomes faster as the graphic processing units (GPUs) increase in speed over time. Currently, our system can reach a full vision cycle speed of 0.3 seconds.
LIGHTING, LIGHTING, LIGHTING
The answer to “What is your biggest headache when you use vision?” always seems to be lighting. 4D Vision is very robust when it comes to changes in the ambient lighting. It uses 2D imaging, where more light is considered better. Any external lighting source can confuse cameras requiring structured light. A good example is factories where natural light hits the factory floor at different times of day.
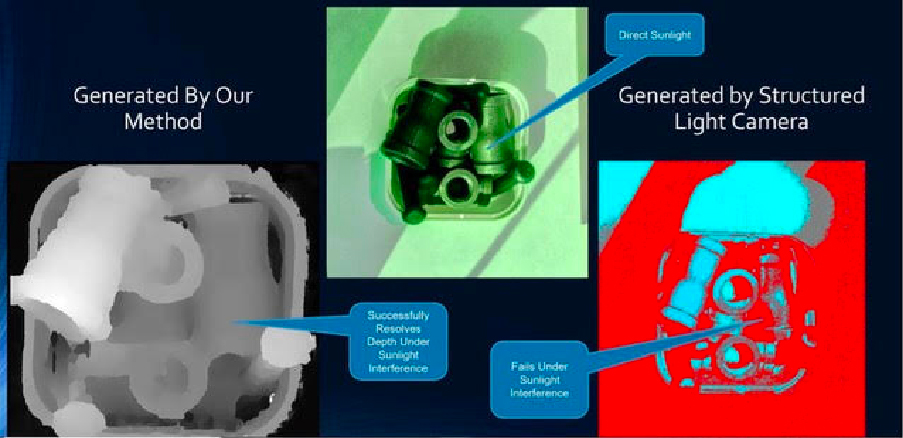
CONSISTENT PERFORMANCE IN THE FACE OF CHALLENGING MATERIAL
4D Vision can handle a much larger variety of material compared to structured light cameras. It doesn’t rely on a structured light pattern and how it is reflected back to the cameras. As a result, it can handle transparent, translucent or even mirror-like objects.